딥러닝(학습 과정 동안 인공 신경망으로서 예시 데이터에서 얻은 일반적인 규칙을 독립적으로 훈련) 기반의 이미지 인식 기술이 빠르게 고도화되고 있다. 하지만 정작 인공지능(AI)이 내부에서 어떤 기준으로 이미지를 인식·판단하는가에 대한 물음에는 명확한 설명이 어렵다. 특히 대규모 모델이 사물을 어떤 개념으로 조합해 결론 내리는지를 분석하는 기술은 단기간에 풀 수 없는 과제로 남는다.
국내 연구팀이 이에 관한 해답을 찾아갈 실마리를 제시했다.

KAIST는 김재철AI대학원 최재식 교수 연구팀이 AI의 판단 근거를 인간이 이해할 수 있도록 모델 내부의 개념 형성 과정을 회로 단위로 시각화한 '설명 가능성(Explainable AI·이하 XAI)' 기술을 개발했다고 26일 밝혔다.
딥러닝 모델 내부에는 인간의 뇌처럼 '뉴런(Neuron)'이라는 기본 계산 단위가 존재한다. 뉴런은 이미지 속 작은 특징(귀 모양, 특정 색, 윤곽선 등)을 감지하는 기능을 갖고 있으며, 값(신호)을 계산해 다음 단계로 전달한다.
반면 회로는 이러한 뉴런 여러 개가 서로 연결돼 하나의 의미(개념)를 함께 인식하는 구조를 말한다. 예컨대 '고양이 귀'라는 개념을 인식하기 위해서는 귀의 윤곽을 감지하는 뉴런과 삼각형 형태를 감지하는 뉴런, 털 색 패턴을 감지하는 뉴런 등이 순차적으로 작동해야 한다. 이들이 하나의 기능 단위(회로)를 이루는 형태다.
다만 최근까지 설명 기술은 "특정 뉴런이 특정 개념을 본다"는 단일 뉴런 중심의 접근이 많았다. 이와 달리 실제 딥러닝 모델은 여러 뉴런이 협력하는 회로 구조로 개념을 형성한다. 연구팀은 이에 착안해 AI의 개념 표현 단위를 뉴런이 아닌 회로 단위로 확장해 해석하는 기술을 제시했다.
연구팀이 개발한 '세분된 개념회로(Granular Concept Circuits·이하 GCC)' 기술은 이미지 분류 모델이 내부에서 개념을 형성하는 과정을 회로 단위로 분석해 시각화하는 새로운 방식이다.
GCC는 뉴런 민감도(Neuron Sensitivity)와 의미 흐름 점수(Semantic Flow)를 계산해 회로를 자동으로 추적한다.
뉴런 민감도는 특정 뉴런이 어떤 특징에 얼마나 민감하게 반응하는지, 의미 흐름 점수는 그 특징이 다음 개념으로 얼마나 강하게 전달되는지를 보여주는 지표다. 이를 통해 색·질감 등 기본 특징이 어떻게 상위 개념으로 조립되는지를 단계적으로 시각화할 수 있다.
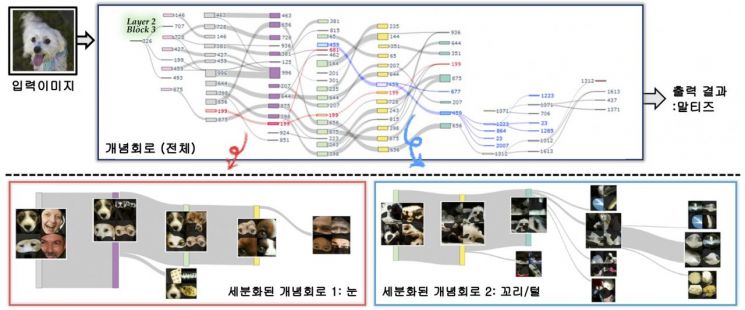
연구팀은 특정 회로를 잠시 비활성화(ablation)하는 실험을 수행한 결과, 회로가 담당하던 개념이 사라지면서 AI의 예측이 실제로 달라지는 현상을 확인했다. 비활성화된 회로가 실제 개념을 인식하는 기능을 수행하고 있음을 직접적으로 입증한 것이다.
이번 연구는 복잡한 딥러닝 모델 내부에서 개념이 형성되는 실제 구조를 세밀한 회로 단위로 드러낸 최초의 연구라는 점에서 의미를 갖는다. 'AI가 어떻게 생각하는지'를 구조적으로 들여다볼 수 있도록 하는 진전을 이뤘다는 평가다.
연구팀은 이를 통해 AI 판단 근거의 투명성을 강화하고 오분류 원인 분석과 편향(Bias) 검출, 모델 디버깅 및 구조개선, 안전·책임성 향상 등 XAI 전반에서 실질적인 응용 가능성을 제시했다.
최 교수는 "연구팀은 그간 복잡한 모델을 단순화해 설명하던 기존 방식과 다르게 모델 내부를 세부 회로 단위로 정밀하게 해석한 최초의 접근 방식을 제시했다"며 "이를 통해 AI가 학습한 개념을 자동으로 추적·시각화할 수 있음을 입증했다"고 말했다.
지금 뜨는 뉴스
한편 이번 연구에는 KAIST 김재철AI대학원 권다희·이세현 박사과정이 공동 제1 저자로 참여했다. 연구 결과는 최근 '국제 컴퓨터 비전 학술대회 (International Conference on Computer Vision, ICCV)'에서 발표됐다.
대전=정일웅 기자 jiw3061@asiae.co.kr
<ⓒ투자가를 위한 경제콘텐츠 플랫폼, 아시아경제(www.asiae.co.kr) 무단전재 배포금지>



















![비트코인 유통량 45% 손실 구간…반등마다 매도벽[비트코인지금]](https://cwcontent.asiae.co.kr/asiaresize/308/2025061315255497648_1749795954.jpg)






{kind=link}
{kind=link}