UNIST Proposes Methodology for Converting and Analyzing Image Data Using LLMs
New Approach for Efficient Data Selection and Multimodal AI Research Published at EMNLP 2025
Artificial intelligence (AI), especially deep learning models, has long been referred to as an inscrutable "black box."
When asked, "AI, why are you here?" it used to respond stubbornly, "Just accept it as it is." But now, AI has finally begun to "explain" itself.
A "black box decoder" that translates the rationale behind AI’s decisions, previously hidden within complex calculations, into human language has been developed. Now, we can confidently ask AI, "Why did you reach that conclusion?"
Although AI can accurately identify a photo as "a bird," it has been difficult to determine exactly "which part" of the image led to that judgment.
Until now, attempts to address this black box problem have mainly focused on dissecting the internal structure of AI models. However, a new approach has emerged: explaining the "data" used for AI training in human language to find solutions.
On December 28, Professor Kim Taehwan’s team at the Graduate School of Artificial Intelligence at UNIST announced that they have proposed a training methodology that explains the AI black box by converting AI training data into "natural language" that humans can understand.
 Research team, (from left) Professor Kim Taehwan, Researcher Kim Chaeri (first author), Researcher Bae Jaeyeon (first author). Provided by UNIST
Research team, (from left) Professor Kim Taehwan, Researcher Kim Chaeri (first author), Researcher Bae Jaeyeon (first author). Provided by UNIST
Previous research on explainable artificial intelligence (XAI) has primarily focused on post-hoc analysis of the internal computation processes or prediction results of trained models.
In contrast, the research team focused on the "data" that serves as the foundation for AI training. By concretizing the features of the data into descriptive statements and analyzing them, they aimed to clarify the model’s decision-making process.
The team first used large language models (LLMs) such as ChatGPT to generate multiple sentences describing the characteristics of objects in photos. To ensure high-quality descriptions without hallucinations, the models were also directed to refer to external knowledge sources such as online encyclopedias.
Not all of the dozens of descriptive sentences generated by LLMs are actually useful for model training. To identify which of these generated descriptions the AI model actually referenced when making correct predictions, the team devised a quantitative analysis metric called the Influence scores For Texts (IFT).
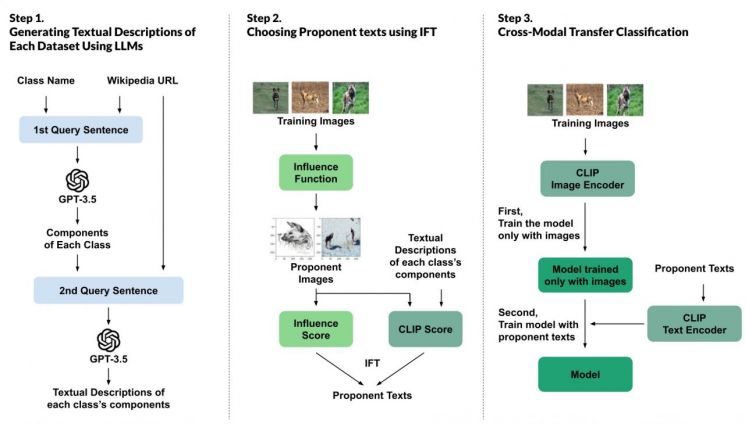 Overview of Data Description Generation, Selection, and Training Process Using Large Language Models (LLM).
Overview of Data Description Generation, Selection, and Training Process Using Large Language Models (LLM).
IFT is calculated by combining two elements: the influence score, which measures the contribution to learning by calculating how much the model’s prediction error changes when a specific descriptive sentence is excluded from the training data; and the CLIP score, which indicates how semantically consistent the textual description is with the actual visual information in the image.
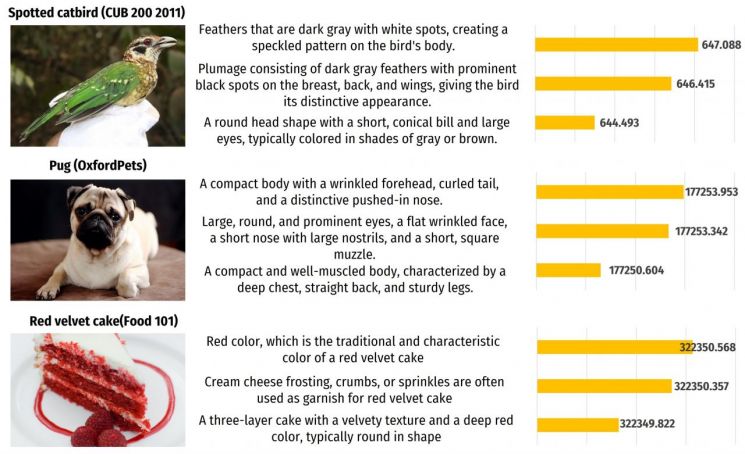 Example of image captions generated by large language models (LLM) and influence scores calculated by artificial intelligence.
Example of image captions generated by large language models (LLM) and influence scores calculated by artificial intelligence.
For example, in a bird classification model, if descriptions of "beak shape" or "feather patterns" receive higher IFT scores than those describing background color, it can be interpreted that the model has learned to identify targets by focusing on features of the beak and feathers.
To verify whether these highly influential descriptions actually help the model achieve correct answers, the research team designed a separate benchmark experiment. They conducted a cross-modal transfer experiment, providing the model with high-influence descriptions during training and performing classification tasks on a new dataset. As a result, using high-influence descriptions led to more stable and higher performance compared to previous methods. This confirms that the descriptions the model actually used during training make a meaningful contribution to its performance.
Professor Kim Taehwan stated, "The method proposed in our research, where AI explains the data it is learning on its own, could fundamentally reveal the complex decision-making processes of deep learning. In the future, this will serve as a foundation for achieving transparent understanding of black box AI systems."
The research results have been accepted as an official paper at EMNLP (Empirical Methods in Natural Language Processing), a leading international conference in the field of natural language processing. This year’s EMNLP was held in Suzhou, China, from November 5 to 9.
© The Asia Business Daily(www.asiae.co.kr). All rights reserved.
![Clutching a Stolen Dior Bag, Saying "I Hate Being Poor but Real"... The Grotesque Con of a "Human Knockoff" [Slate]](https://cwcontent.asiae.co.kr/asiaresize/183/2026021902243444107_1771435474.jpg)















{kind=link}
{kind=link}
{kind=link}