Professor Kim Jongrak’s Sogang University Team Compares Korean and Overseas AI Models
Only Solar Pro-2 Scores 58 Among Korean Models... Others Remain in the 20s
An evaluation of the mathematical College Scholastic Ability Test (CSAT) and essay problem-solving abilities of large language models (LLMs) both in Korea and abroad has revealed that Korean teams’ models perform significantly worse than their international counterparts.
On December 15, Professor Kim Jongrak’s research team from the Department of Mathematics at Sogang University announced the results of having five major LLMs from Korea’s national AI challenge teams, as well as five overseas models including ChatGPT, solve 20 CSAT math questions and 30 essay questions.

For the CSAT questions, the research team selected the five most difficult items each from the common subject, probability and statistics, calculus, and geometry, making a total of 20 questions. For the essay questions, they prepared 10 previous questions from Korean universities, 10 Indian college entrance exam questions, and 10 mathematics questions from the University of Tokyo’s Graduate School of Engineering entrance exam, totaling 30 essay questions. In all, 50 questions were given to 10 models to solve.
The Korean models tested included Upstage’s “Solar Pro-2,” LG AI Research’s “Exaone 4.0.1,” Naver’s “HCX-007,” SK Telecom’s “A.X 4.0 (72B),” and NCSoft’s lightweight model “Llama Barco 8B Instruct.”
The overseas models included GPT-5.1, Gemini 3 Pro Preview, Claude Opus 4.5, Grok 4.1 Fast, and DeepSeek V3.2. The results showed that the overseas models scored between 76 and 92 points. Among the Korean models, only Solar Pro-2 scored 58 points, while the others recorded low scores in the 20s. Llama Barco 8B Instruct received the lowest score, with just 2 points.
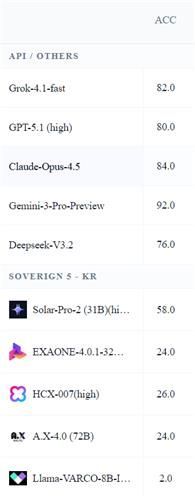 Results of solving 20 College Scholastic Ability Test questions and 30 essay questions. Professor Kim Jongrak's team
Results of solving 20 College Scholastic Ability Test questions and 30 essay questions. Professor Kim Jongrak's team
The research team explained that the five Korean models generally failed to solve most problems through simple reasoning, so they were designed to use Python as a tool to improve accuracy, yet the results remained poor.
Furthermore, the team created a custom problem set called “EntropyMath,” consisting of 100 questions with difficulty levels ranging from undergraduate to professor-level research. They selected 10 questions from this set and had the 10 models attempt them. Once again, the overseas models scored between 82.8 and 90 points, while the Korean models scored between 7.1 and 53.3 points.
When the models were allowed up to three attempts per problem, with a correct answer on any attempt counted as a pass, Grok achieved a perfect score, and the other overseas models scored 90 points. Among the Korean models, Solar Pro-2 scored 70 points, Exaone scored 60, HCX-007 scored 40, A.X 4.0 scored 30, and Llama Barco 8B Instruct scored 20.
Professor Kim stated, “Many people around me asked why there was no evaluation of the five Korean sovereign AI models on CSAT questions, so our team conducted the test. We found that the level of domestic models lags far behind the overseas frontier models.”
© The Asia Business Daily(www.asiae.co.kr). All rights reserved.
![Clutching a Stolen Dior Bag, Saying "I Hate Being Poor but Real"... The Grotesque Con of a "Human Knockoff" [Slate]](https://cwcontent.asiae.co.kr/asiaresize/183/2026021902243444107_1771435474.jpg)















{kind=link}