A Multimodal Learning Method Without Data Alignment Developed by Professor Sunghwan Yoon's Team
Expected to Reduce Data Construction Costs and Enable Applications in Healthcare, Autonomous Driving, and More
A new learning method has been developed that enables artificial intelligence to be trained on one type of data and thereby facilitate learning of another type of data.
This approach eliminates the need for data alignment, which was previously considered essential for learning from different types of data. As a result, it is expected to reduce the costs associated with building data sets.
On May 7, a team led by Professor Sunghwan Yoon at the UNIST Graduate School of Artificial Intelligence announced that they have developed an AI multimodal learning technology capable of promoting the training of models for different data types using only a single data modality, without the need for data alignment or matching.

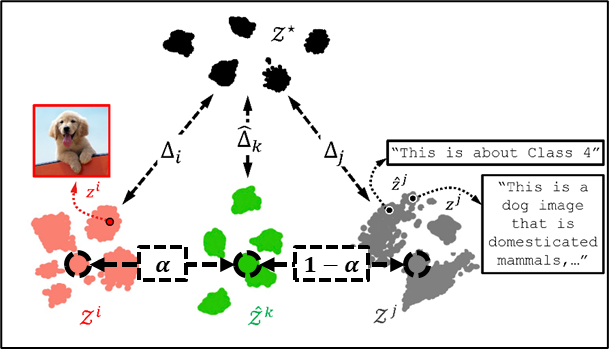
Multimodal learning is a method that combines different data modalities, such as audio, images, and text, to enable integrated understanding and processing. Traditionally, multimodal learning requires aligning various modalities and labeling them in pairs, which consumes significant time and resources. Moreover, a lack of clearly paired data can lead to degraded performance.
The learning method proposed by the research team enables multimodal learning even with unpaired data. This can reduce the time and costs involved in building AI assistants that understand emotions by analyzing both speech and human facial expressions, or in developing medical AI that diagnoses by integrating CT images and medical records like a physician.
The team conducted experiments in which a text model assisted image model training, and an audio model enhanced the performance of a language model. They observed improved accuracy compared to existing methods, confirming the effect of cross-modality learning facilitation. Notably, the AI's performance improved even for combinations with little direct correlation, such as audio and images.
Jaejun Lee, the first author of the study, explained, "The fact that performance improved even for seemingly unrelated combinations of audio and images is an intriguing result that challenges conventional assumptions about multimodal learning methods."
Professor Sunghwan Yoon stated, "This technology has high potential for application in various fields where it is difficult to secure aligned data sets, such as healthcare, autonomous driving, and smart AI assistants."
This research has been accepted for presentation at ICLR (International Conference on Learning Representations) 2025, one of the world's top three artificial intelligence conferences. ICLR 2025 was held in Singapore from April 24 to April 28, and 3,646 papers were accepted out of 11,672 submissions.
© The Asia Business Daily(www.asiae.co.kr). All rights reserved.
![Clutching a Stolen Dior Bag, Saying "I Hate Being Poor but Real"... The Grotesque Con of a "Human Knockoff" [Slate]](https://cwcontent.asiae.co.kr/asiaresize/183/2026021902243444107_1771435474.jpg)
















{kind=link}
{kind=link}