Professor Jaeyoung Shim's Team at UNIST Graduate School of Artificial Intelligence Develops 3D Point Cloud Dataset Distillation Technique
Simultaneously Resolves Data Order Inconsistency and Rotational Variability, Demonstrating General Performance... Paper Accepted at NeurIPS
"Say goodbye to heavy AI!" UNIST drastically shortens 3D model training time with a 'speed revolution.' The amount of training data has been reduced, yet the AI model's performance remains top-tier.
A new technology has emerged that maximizes training efficiency for object recognition artificial intelligence (AI) models, which serve as the "eyes" of autonomous vehicles and robots, by summarizing the amount of data required for training while preserving performance.
This advancement allows for a significant reduction in both the time and computational costs involved in AI model development.
The research team led by Professor Jaeyoung Shim at the UNIST Graduate School of Artificial Intelligence has developed a 'dataset distillation' technology that effectively compresses 3D point cloud data to enhance training efficiency.
 Research team (from left) Professor Jaeyoung Shim, Researcher Jaeyoung Lim (first author), Researcher Dongwook Kim (first author). Provided by UNIST
Research team (from left) Professor Jaeyoung Shim, Researcher Jaeyoung Lim (first author), Researcher Dongwook Kim (first author). Provided by UNIST
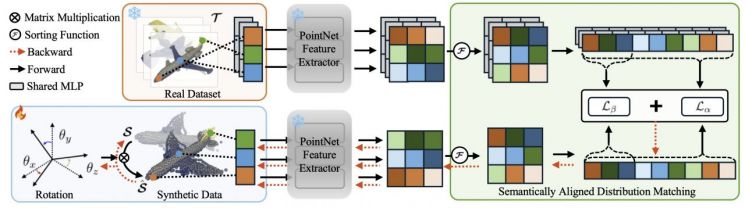
Dataset distillation is a technology that extracts only the essential points from large-scale training data to create new 'summary data.' 3D point cloud data is considered a particularly challenging type of data for applying this technology. This is because 3D point cloud data represents objects as points, the arrangement of which has no fixed order, and the objects are often rotated.
These characteristics become critical obstacles during the process of generating summary data. Dataset distillation improves the quality of summary data by 'comparing' the features of the original and summary datasets. However, due to the aforementioned properties, proper comparison (matching) is impossible. As a result, comparisons may be made between irrelevant parts, or the same object may be recognized as a different one, leading to summary data that incorporates incorrect information.
The research team has developed a dataset distillation technology that solves this problem. The technology incorporates a loss function (SADM) that automatically arranges the semantic structure of unordered point data, as well as a learnable rotation technique that enables the AI to optimize the rotation angles of objects during training.
The developed dataset distillation technology has been shown to maintain model accuracy even when the data is reduced to less than one-tenth of the original size. In particular, for a specific dataset (ModelNet40), the model achieved an 80.1% recognition accuracy when trained on summary data that was just 1/25th the size of the original, compared to 87.8% when trained on the full dataset. This demonstrates that training efficiency and performance can be balanced even at high compression rates.
Professor Jaeyoung Shim stated, "This technology fundamentally resolves the matching errors that previous methods faced due to the disordered structure and rotational uncertainty of 3D point data," adding, "It can significantly reduce AI training costs and time in fields that require large-scale 3D data, such as autonomous driving, drones, robotics, and digital twins."
The results of this research have been officially accepted as a paper at the Neural Information Processing Systems (NeurIPS) 2025, one of the three most prestigious international conferences in the field of artificial intelligence.
This research was supported by the National Research Foundation of Korea and the Institute of Information & Communications Technology Planning & Evaluation under the Ministry of Science and ICT.
The 2025 Neural Information Processing Systems Conference will be held in San Diego, United States, from December 2 to 7.
© The Asia Business Daily(www.asiae.co.kr). All rights reserved.
![Clutching a Stolen Dior Bag, Saying "I Hate Being Poor but Real"... The Grotesque Con of a "Human Knockoff" [Slate]](https://cwcontent.asiae.co.kr/asiaresize/183/2026021902243444107_1771435474.jpg)
















{kind=link}
{kind=link}