Performance Evaluation of Generative AI Models
Development of 'BigZen Bench' Wins Best Paper Award
Open Source Evaluator Also Released
LG AI Research Institute has won the 'Best Paper Award' at the 2025 North American Chapter of the Association for Computational Linguistics (NAACL), one of the most prestigious conferences in the field of Natural Language Processing (NLP).
LG AI Research Institute announced on the 30th that, following last year's 'Social Impact Award' at NAACL 2024 for a research paper analyzing cultural bias in AI models and discussing the stability and fairness of artificial intelligence (AI) systems, this year its benchmark research paper evaluating the performance of generative AI models has received the Best Paper Award.
LG AI Research Institute has demonstrated the competitiveness of Korean AI technology by winning the Best Paper Award, which is given to only one paper selected from over 1,400 papers accepted at NAACL 2025. The Best Paper Award is presented to the most innovative and significant research of the year that either proposes a new research direction or solves an important problem in the field of natural language processing.
Seungwon Kim, the first author of the paper and a doctoral student at Carnegie Mellon University, developed the 'BigZen Bench' for evaluating the performance of generative AI models during his internship at the Hyper Intelligence Lab of LG AI Research Institute. He collaborated with Moontae Lee, head of the Hyper Intelligence Lab, Kyungjae Lee, leader of the Data Squad, and Professor Minjoon Seo's research team at KAIST (Korea Advanced Institute of Science and Technology), leading to the Best Paper Award.
This research, led by LG AI Research Institute and Professor Minjoon Seo's team at KAIST, involved researchers from several universities, including Yonsei University, Cornell University, University of Illinois, MIT, and University of Washington.
Existing evaluation methods for generative AI models rely on abstract conceptual indicators such as 'usefulness' and 'harmlessness.' This leads to discrepancies with human evaluations and makes it particularly difficult to measure the detailed competencies of AI models.
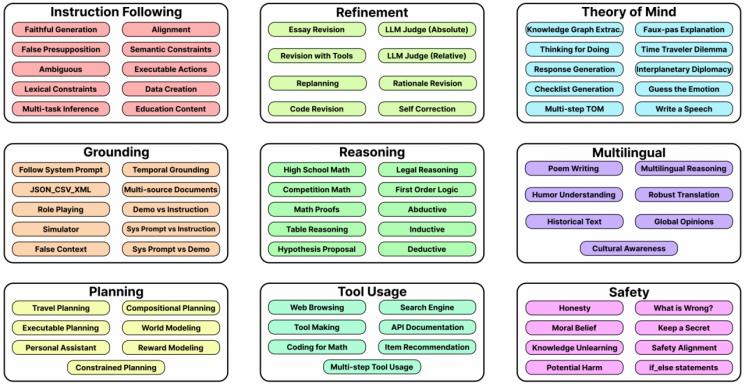
BigZen Bench classifies the core competencies that generative AI models should possess into nine categories, including instruction following, logical reasoning, tool use, safety, and understanding diverse languages and cultural contexts. It evaluates performance across 765 items covering 77 specific roles. This approach is designed to mimic human evaluation, which considers various surrounding circumstances and subjective factors when using and assessing generative AI models, in order to produce results similar to those of human evaluators. Using BigZen Bench, LG AI Research Institute evaluated 103 generative AI models and, through cross-validation with expert groups, demonstrated a high level of reliability and validity, confirming its potential as a new benchmark.
Moontae Lee, head of the Hyper Intelligence Lab, stated, "BigZen Bench is designed to objectively and comprehensively evaluate the diverse capabilities of generative AI, overcoming the limitations of existing benchmarks and aligning with the sophisticated evaluation criteria of humans to accurately assess AI model capabilities." Professor Seo emphasized, "The greatest advantage of BigZen Bench is its ability to quantify the practical utility that users actually experience when evaluating generative AI models. Achieving good results on BigZen Bench means that the generative AI model is likely to deliver satisfactory performance in real-world use."
During the research process, LG AI Research Institute also released Prometheus-2, one of the five AI models used as evaluators, as open source. Prometheus-2 performed the evaluator role with a level of reliability comparable to GPT-4, the highest-performing global commercial model. LG AI Research Institute is also conducting follow-up research to automatically evaluate the performance of generative AI models on specific items during the development process, based on BigZen Bench.
© The Asia Business Daily(www.asiae.co.kr). All rights reserved.
![Clutching a Stolen Dior Bag, Saying "I Hate Being Poor but Real"... The Grotesque Con of a "Human Knockoff" [Slate]](https://cwcontent.asiae.co.kr/asiaresize/183/2026021902243444107_1771435474.jpg)
















{kind=link}