구글 배포 한국어 언어모델 대비 평균 4.5% 성능 우수
[아시아경제 김철현 기자] 인공지능(AI) 서비스 개발을 돕는 최첨단 한국어 언어모델이 공개됐다. 이로써 AI 비서, AI 질의응답, 지능형 검색 등 한국어를 활용한 AI 서비스 개발이 한층 고도화될 것으로 전망된다.
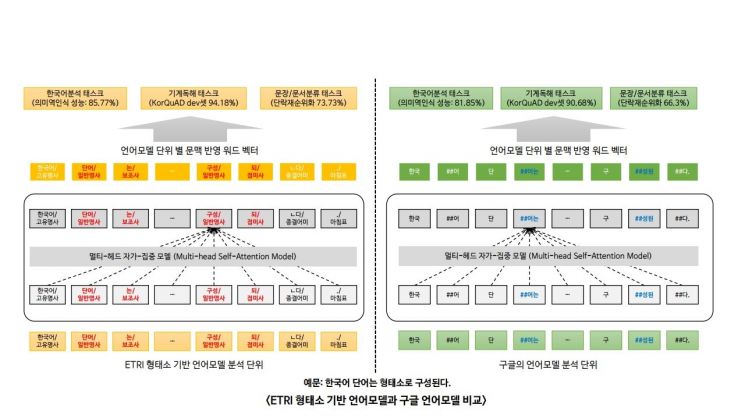
한국전자통신연구원(ETRI)은 11일 최첨단 한국어 언어모델 '코버트'를 홈페이지를 통해 공개했다고 밝혔다. 이번에 공개한 모델은 구글의 언어표현 방법을 기반으로 더 많은 한국어 데이터를 넣어 만든 언어모델과 한국어의 '교착어' 특성까지 반영해 만든 언어모델 등 두 종류다.
언어처리를 위한 딥러닝 기술을 개발하기 위해서는 텍스트에 기술된 어절을 숫자로 표현해야 한다. 이를 위해 그동안 언어를 활용한 서비스를 개발하는 기관에서는 주로 구글의 다국어 언어모델 '버트'를 사용했다. 구글은 40여 만 건의 위키백과 문서 데이터를 사용해 한국어 언어모델을 개발했다. 하지만 ETRI 연구진은 여기에 23GB에 달하는 지난 10년간의 신문기사와 백과사전 정보를 더해 45억개의 형태소를 학습시켜 구글보다 많은 한국어 데이터를 기반으로 언어모델을 만들었다. 또 한국어의 의미 최소 단위까지 고려해 한국어 특성을 최대한 반영한 언어모델을 개발했다.
지금 뜨는 뉴스
개발된 언어모델은 성능을 확인하는 5가지 기준에서 구글이 배포한 한국어 모델보다 평균 4.5% 가량 우수했다. 특히 '단락 순위화' 기준에서는 7.4%나 높은 수치를 기록했다. 연구진의 언어모델을 활용하면 서비스 성능 및 경쟁력을 높일 수 있어 개발자들의 많은 활용이 이뤄질 것으로 기대된다. 김현기 ETRI 박사는"한국어에 최적화된 언어모델을 통해 한국어 분석, 지식추론, 질의응답 등의 다양한 한국어 딥러닝 기술의 고도화가 가능할 것으로 기대된다"고 말했다.
김철현 기자 kch@asiae.co.kr
<ⓒ투자가를 위한 경제콘텐츠 플랫폼, 아시아경제(www.asiae.co.kr) 무단전재 배포금지>






![전문가 4인이 말하는 '의료 생태계의 대전환'[비대면진료의 미래⑥]](https://cwcontent.asiae.co.kr/asiaresize/319/2026013014211022823_1769750471.png)











![北 김정은 얼굴 '덥석'…'예뻐해 함께 다닌다'는 김주애가 후계자? 아들은?[양낙규의 Defence Club]](https://cwcontent.asiae.co.kr/asiaresize/308/2023042407464898154_1682290007.jpg)


![수능 마친 고3들 '필수 코스'였는데…요즘 청년들, 면허 취득 미룬다는데[세계는Z금]](https://cwcontent.asiae.co.kr/asiaresize/308/2026021510301943056_1771119019.jpg)



![잘못 봤나? 가격표 다시 '확인'…등장할 때마다 화제되는 이부진 '올드머니룩'[럭셔리월드]](https://cwcontent.asiae.co.kr/asiaresize/308/2026010919492186081_1767955761.jpg)